(Advanced user only!)
Events often have a lot of data associated with them and the data varies greatly between events. In order to accommodate this in the database, each row in the Event table contains a field that holds an XML string containing all of the event's data. Other fields contain data that has been extracted from the XML and "promoted" to their own fields. These additional fields make searching for and filtering of events much more efficient. The problem is that, if you promote everything, there would be far too many fields for the database to handle. This problem is especially apparent when you consider all of the possible item types that can appear in a PIMs Log.
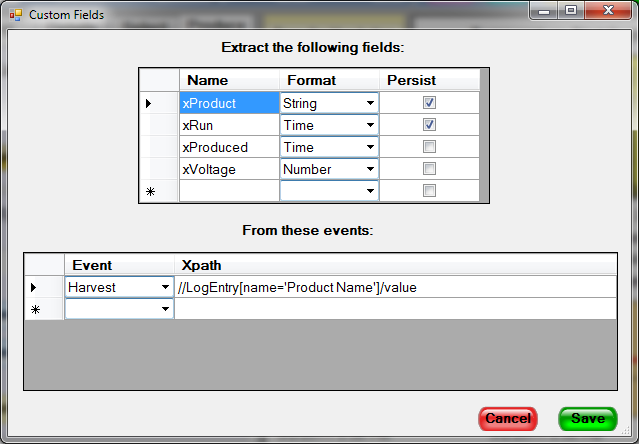
PIM Control solves this problem by automatically promoting a standard set of fields and providing a mechanism that lets users (usually the user maintaining the Company Database) define their own additional fields as needed. These field definitions involve naming the new field, specifying its type, and describing how to extract the corresponding data from the XML. These definitions are then saved on the Company database. When PIM Control starts-up, it reads these definitions and, when it reports a new event to the database, does the specified extractions.
These new fields can be added to the actual database ("persisted") or can be extracted only as needed by the Pivot Report Tool. Generally, if you need a field while filtering the
Select View, you should persist the field. Otherwise, uncheck the Persist box.
Field extraction is specified using a standard XML processing language called XPATH. A description of XPATH is beyond the scope of this document but you can get a lot done with just a few
XPATH examples as guidance. In the image below, the xProduct field is added to the database as a String valued field. It is extracted from Harvest events by searching for a Log entry with the name "ProductName".